Standardese - a (work-in-progress) nextgen Doxygen
Documentation is essential. Without knowing what certain functions/classes/… do, it is very difficult to use any code properly.
Tools can help to provide a documentation. They can extract information from the source code and combine it with manually written information to generate documentation in a human readable output format.
There is a problem though: The current tools for C++ documentation aren’t that great. This post explains why and provides a (work-in-progress) solution.
TL;DR: standardese
What’s the problem?
Doxygen is the de facto standard for C++ documentation. Almost every open source library with documentation, mine included, uses it in some way. It is a great tool. It scans the code for documentation comments and pairs them with the function signatures etc. to provide a documentation in various formats like HTML.
Its output can be greatly customized and there are various projects combining it with other renderers like Breathe to use the Python tool Sphinx. And it is also possible to combine it with BoostBook or QuickBook.
But there is a problem: Doxygen isn’t exactly perfect.
Everyone who’s used it can agree with me. It sometimes has its problems or rough edges. It will work in the end, but it’s ugly.
I really do not want to bash on Doxygen here. It is an awesome tool.
But I probably don’t need to bash on Doxygen. Those who’ve used it extensively probably know what I mean.
And this isn’t Doxygens fault alone. Yes, it is old; license dates back to 1997 - before C++ standardization! So in some ways it hasn’t adapted properly to the recent changes in C++.
But: C++ isn’t exactly easy to document with a tool.
Documenting C++ is hard
C++ is a very complex language and there are tons of ways to use and combine its dozens of features. When generating documentation there are many things that needs to be considered:
This list is by far not exhaustive, I’m sure you can think of your own problems you’ve encountered with automatic documentation tools.
-
Parameters that are only there to allow SFINAE. They should be hidden when showing the function signature - they’re not exactly pretty and might confuse beginners. Instead the requirements should be put into the documentation.
-
Implementation defined types. Some return types or typedef’ed types are “implementation defined” as the standard puts it. Those detail types are proxies or handles to the underlying OS. They shouldn’t appear in the signatures either.
-
There are tons of ways to accomplish the same things. Those details should be abstracted away in the documentation. Examples are: function objects vs free functions or constants vs enumerations.
-
On a related note: C++ doesn’t provide a way to get “strong typedefs” that generate new types. So sometimes a typedef is meant to be a new type, sometimes an alias for another type. A documentation should reflect that.
-
Some classes - especially in generic code - have bases that are only there to provide the empty-base-optimization. Those should be hidden from the base class list. Other base classes are only there to get an interface. A famous example is
std::tuple, it will likely use inheritance to implement the recursion over its arguments Those base classes shouldn’t appear either, instead they should be inlined into the class. -
Documentation generation usually ignores
privatemembers because they aren’t part of the interface. But the NVI pattern proposes that allvirtualfunctions should beprivateso simply ignoring them doesn’t work. Similarily pre-C++11 code declares and not defines functions to delete them. They should also be mentioned in the documentation instead of ignored. -
Before the concept TS gets merged we need a way to document the concepts a template parameter has to fulfill. A documentation tool should account for that.
-
There is a lot of boilerplate code like almost identical
constand non-constgetters or overloads for all comparision operators. They only need to be documented once.
So far I’ve worked around these problems by adapting my use of the language to the tool, i.e. Doxygen. For example I have macros to mark things as implementation defined, base classes as EBO or parameters for SFINAE or simply adapt my interfaces.
To be fair: Using a macro for SFINAE parameters also makes your code look nicer. But you get my point.
But this is wrong: You shouldn’t adapt your use to tools, tools should adapt to your use! Tools should make your life easier, not harder. I - and I am not alone - want a Doxygen that can handle my use of C++ without a macro-clusterfuck and hacks.
I couldn’t find any, so I started to write my own.
My aim
My aim is clear: I want a tool that can handle C++. But I couldn’t just fix Doxygen because Doxygen doesn’t provide the exact kind of documentation I want natively.
Plus I want to have fun writing it, after all, it is my free time. Fixing a 19-year-old code base won’t be fun.
I really like the way C++ standard documents the library.
For example this is the documentation for std::swap:
template<class T> void swap(T& a, T& b) noexcept(see below );
1 Remark: The expression inside noexcept is equivalent to:
is_nothrow_move_constructible<T>::value && is_nothrow_move_assignable<T>::value
2 Requires: Type T shall be MoveConstructible (Table 20) and MoveAssignable (Table 22).
3 Effects: Exchanges values stored in two locations.
It has an indirect way of describing what a function does through the “Effects”. I really like it. It is nice and structured.
Doxygen encourages a more direct way. When using Doxygen you can result in the following:
I’ve created a new project and used the default configuration.
Sorry, I cannot properly embed images apparently.
I won’t pick on the fact that Doxygen incorrectly marks the function with the noexcept flag,
this could be considered a bug.
I do pick on the fact that Doxygen doesn’t (afaik) provide a native way to specify requirements,
so I’ve used \tparam to document the requirement inside the template parameter.
Doxygen overall encourages this direct style of documenting each entity.
This results in information spread over the entire documentation.
It’s a minor issue and can be avoided simply by not using \param in this case.
But as I see it this is the style Doxygens design encourages.
Both documentations give the exact same information. But I much rather read the first kind of documentation.
This is just my personal opinion, yours can differ.
But my aim is also to generate documentation in a similar way the C++ standard does it. This was actually my major motiviation to start my own tool, hence its name - Standardese.
So … What does it do?
So I’ve started working on Standardese about two weeks ago.
I’ve implemented parsing of any* C++ entity you might want to document with the help of libclang.
“Any” here means everything except for variable and alias templates, my libclang version doesn’t support those yet, and any weird combination of features I might have overlooked.
Libclang greatly helped there and allowed me to get something usable without having to write an entire C++ parser from scratch.
It still has some lacking features so I had to write parsers to get some information like explicit or noexcept but without it I wouldn’t be at this point right now.
My own C++ AST is generated containing the information needed to generate documentation.
On top of that is a very primitive comment parser that currently only looks for section markers like \effects or \throws.
A customizable output system then allows serialization in Markdown.
The generation implemented so far is only per-file generation. It recursively visits each C++ entity in a given file, generates a synopsis by serializing it, and formats the documentation. Later versions will also include chapters but not the current prototype.
All this is implemented in a library. I’ve seen that Doxygen is used for myriads of output formats and is merely a frontend for C++ documentation parsing. The goal of the Standardese library is to become a better and more generic frontend that should be customizable and extensible.
There is also the Standardese tool that drives the library. It reads filenames and configurations and generates documentation for each file given to it (or in a given folder) and uses the library to generate the documentation.
So… How does it look?
This is how you would document swap() with Standardese:
/// \effects Exchanges values stored in two locations.
/// \requires Type `T` shall be `MoveConstructible` and `MoveAssignable`.
template <class T>
void swap(T &a, T &b) noexcept(is_nothrow_move_constructible<T>::value &&
is_nothrow_move_assignable<T>::value);
You can use Markdown in comments because everything in the comments will just be copied verbatim to the output. But I do plan on supporting similar highlighting.
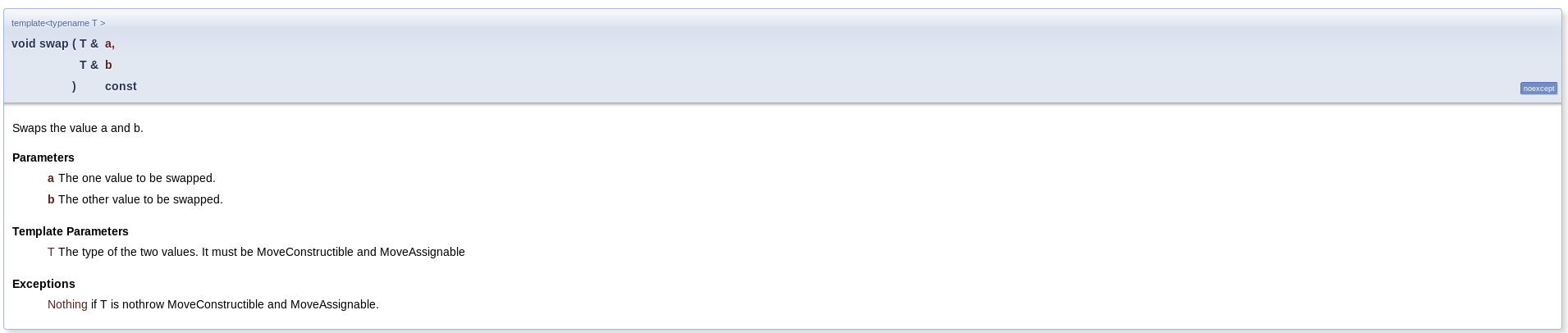
And the current prototype will generate the following documentation:
Header file swap.cpp
#include <type_traits>
namespace std
{
template <typename T>
void swap(T & a, T & b) noexcept(is_nothrow_move_constructible<T>::value &&is_nothrow_move_assignable<T>::value);
}
Function template swap<T>
template <typename T>
void swap(T & a, T & b) noexcept(is_nothrow_move_constructible<T>::value &&is_nothrow_move_assignable<T>::value);
Effects: Exchanges values stored in two locations.
Requires: Type T shall be MoveConstructible and MoveAssignable.
For a more complex example see here: https://gist.github.com/foonathan/14e163b76804b6775d780eabcbaa6a51
This sounds/looks awesome! Can I go and use it?
You could but I wouldn’t recommend using it for actual documentation generation… yet. As mentioned this is just an early prototype.
The library lacks documentation (ironic I know) and its interfaces are highly unstable. There might be bugs everywhere although I do have unit tests for parsing. It is just a dumb generator handling none of the C++ problems I mentioned earlier and lacks important features such as linking between entities.
It basically lacks all support for all the hard C++ I’ve mentioned above. But I do plan on supporting them in future versions.
I’ve still decided to publish it though. I want your feedback on it, please share any thoughts with me. I plan on using Standardese for the documentation for my libraries in the future and my goal is that you do as well. For that please talk to me about things you wish to have.
If you’re interested I will post regular updates on it and motivation behind design decisions. I have nothing else to do currently and will push on it, in the summer a 1.0 will be done.
It would also be helpful if you ran the parser on your own codebase to see if you ran into any bugs.
Spoiler alert: You will and there will be many.
Get the code here and have fun breaking it. :)
Please share and spread the word!
This blog post was written for my old blog design and ported over. If there are any issues, please let me know.